AI and Predictive Performance Analytics: What Works, What Doesn't, and Why the Best Tool in 2026 Is Still a Sceptical Human

Prefer listening? Play the audio version:
This is the first piece from the dive-in series following each aspect highlighted in the inagual article. Here we will focus on the technologies actually changing elite sport in 2026. Each deep-dive takes one area, names the teams and platforms, and reads the evidence honestly – separating what the published record actually supports from what the marketing claims. This is not a manual written from the touchline; it is a map of where the evidence is strong, where it is thin, and what a performance department should ask before letting any of it near a decision.
If you had to pick the area where the gap between hype and substance is widest in elite sport, AI for injury prediction would be near the top. The promise is seductive: feed a model your GPS, wellness questionnaires, sleep and medical history, and it tells you who’s about to get hurt before they do. The reality, as the evidence has matured over three years, is more sobering – and the most rigorous voices in the field have grown markedly more impatient with the marketing.
Some context. Across the top five European leagues in 2023/24, thousands of injuries were recorded; one recent preprint put the figure at 4,123 injuries and around €732 million (Huth et al., 2025). The exact number is contested; the order of magnitude is not. That is the size of the problem AI is sold as the answer to – and a big problem is a reason for better evidence, not an excuse for worse.
What the published evidence actually says
Start with the methodologists, because their conclusions are blunt and they frame everything else. In 2022, Bullock and colleagues evaluated every published musculoskeletal injury-prediction model in sport – 30 studies, 204 models – against PROBAST, the standard risk-of-bias tool (Bullock et al., 2022a). The findings are damning: not one model had been externally validated, just 2% were at low risk of bias, only 7% of studies reported calibration, and no machine-learning study published its code. Their conclusion – no model could be recommended for use in practice.
A 2024 commentary in Sports Medicine – Open, co-authored by Bullock, Hughes, Collins, Impellizzeri and Patrick Ward, a leading practitioner-scientist in elite sport analytics, went further (Bullock et al., 2024). Replying to a paper calling the field’s models “quite sound,” they wrote: “this is not true.” Their point was specific – discrimination metrics like AUC and sensitivity are not enough; calibration, external validation and decision utility are what matter – and they warned against two shortcuts the field leans on: naïve class-rebalancing and purely classificatory models.

Hold that warning; one of the most useful recent peer-reviewed examples for stress-testing the field does both.
The base-rate problem, with the arithmetic vendors skip
Non-contact soft-tissue injuries are rare – a fraction of a percent of player-days. When the event is that rare, even a model with good sensitivity and specificity throws off a flood of false positives, and the only number that tells you whether an alert is worth acting on is the positive predictive value (PPV): when the model says “high risk,” how often is it right?
Work the most recent independent example through. Freitas and colleagues, in PLOS ONE (January 2025), trained models on 34 male professional footballers from one Portuguese club across a single season (Freitas et al., 2025). The best reported sensitivity ~71% and specificity ~74% – respectable on a slide. But injuries were just 0.20% of observations. At the observation level, using the study’s reported prevalence, sensitivity and specificity, the implied PPV lands near 0.6%. In that framing, more than 99 of every 100 positive flags would be false positives.
Turn each flag into a benched player or a cut session and the operational cost becomes obvious: you risk disrupting many healthy athletes to catch very few true cases.
And here the warning comes home. The Freitas model is built on exactly the shortcuts Bullock flagged: it works a severely imbalanced dataset with undersampling and cost-sensitive learning, sets its threshold off the ROC curve, and reports no calibration. van den Goorbergh and colleagues showed in simulation that class-imbalance corrections systematically inflate the predicted probability of the rare event without improving real discrimination (van den Goorbergh et al., 2022). Worse, the authors note outlier removal, standardisation and feature selection were done on the complete dataset before the train/test split – a textbook route to information leakage. None of this makes the study worthless; it makes it an exploratory single-club pilot, not the robust independent anchor a performance director should lean on. We flag it because the trade press does not.
The honest read: at the population level these models may help shift squad-wide injury burden when deployed carefully – but even that is a hypothesis the strongest review declined to endorse. At the individual-athlete, individual-week level, they remain a prompt to go and look at someone, not a verdict. Treating the second as the first is how trust gets destroyed inside a club.
Vendor case studies are signals, not evidence
Read the trade-press numbers with the same discipline. Zone7 (acquired by Svexa in early 2024) reports that across eleven clubs from 2019–2021 its models flagged 306 of 423 injuries up to seven days out – 72.4% sensitivity (Zone7, 2022); La Liga’s Getafe told ESPN, via then Head of Performance Javier Vidal, that injury volume fell 40% in year one and 66% in year two. Worth reading as market signals – but not evidence of causal effect. A club’s injury burden moves for many reasons in a season: staff and tactical changes, fixture congestion, squad turnover, rehab quality, a shifting injury definition, or regression to the mean after a bad year. These figures are retrospective, vendor-reported and uncontrolled – exactly the kind of evidence profile that would sit low in the hierarchy Bullock’s critique points us toward. The right way to hold a vendor case study is as a hypothesis to test, sitting at the bottom of an evidence hierarchy that runs up through peer-reviewed internal validation, external validation in a comparable population, prospective validation in the actual deployment, and finally demonstrated decision impact. Almost all injury-prediction evidence in 2026 – vendor and academic alike – sits in the bottom two tiers.
The workload-ratio problem nobody wants to talk about
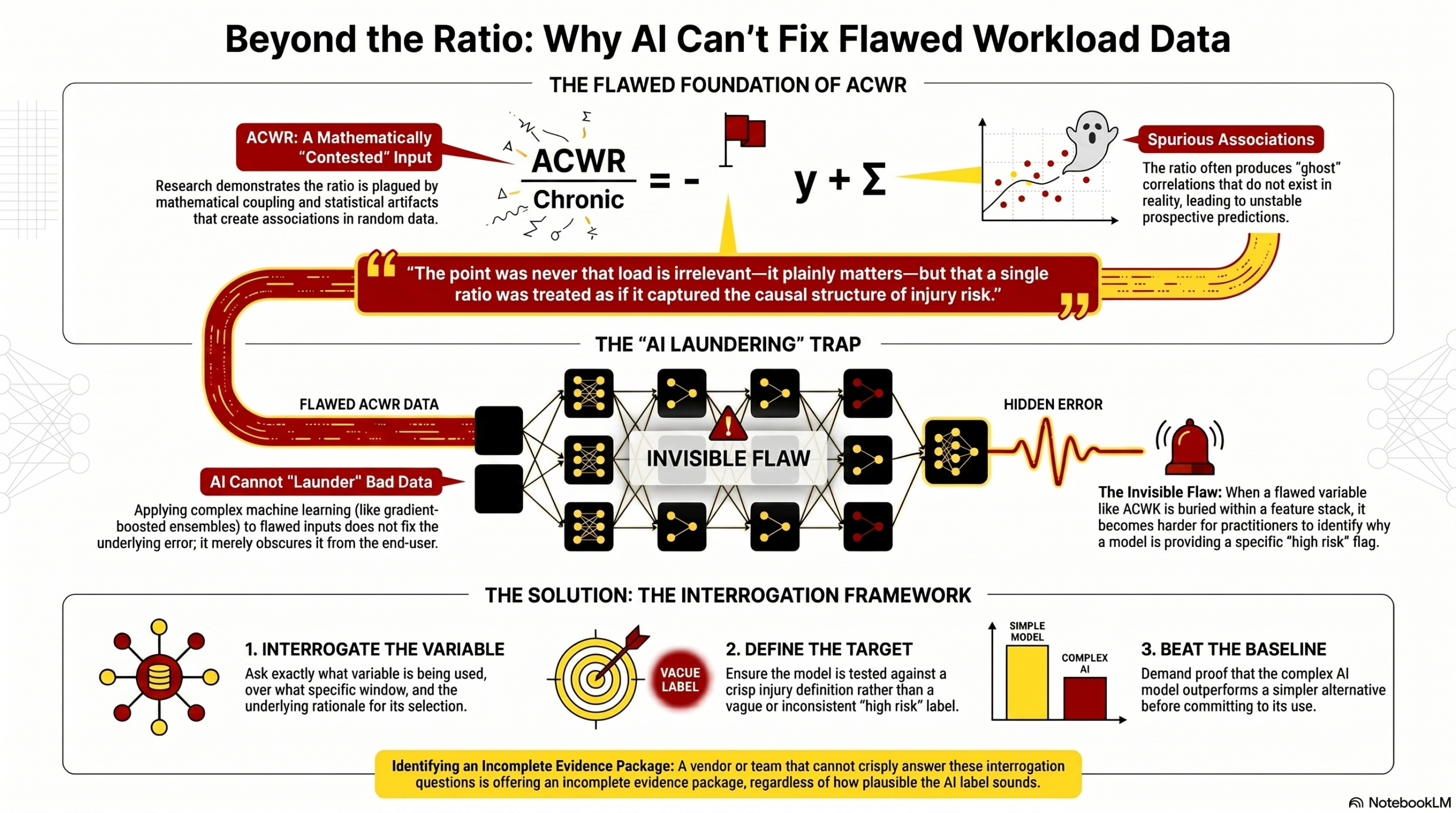
Much commercial AI risk-modelling still leans, somewhere in the feature stack, on variables descended from the acute:chronic workload ratio (ACWR). Its problems are well documented: Impellizzeri and colleagues showed mathematical coupling, unstable prospective prediction and statistical artifacts that produce spurious associations even in random data (Impellizzeri et al., 2020), and a 2021 follow-up argued the underlying theory should be dismissed (Impellizzeri et al., 2021). The point was never that load is irrelevant – it plainly matters – but that a single ratio was treated as if it captured the causal structure of injury risk.
The same lesson applies to AI: dropping a gradient-boosted ensemble on a contested input does not launder the flaw, it buries it a layer deeper. Workload variables need interrogating, not banning – what variable, over what window, with what rationale, against what injury definition, and does it beat a simpler alternative? A team that can answer crisply is worth talking to; one that cannot should be treated as offering an incomplete evidence package, however plausible the label.
Prediction is not intervention
Even a perfectly calibrated risk score does not tell you what to do – and that is where the Huth and colleagues 2025 preprint earns its place, not as proof prediction works but for reframing it as a decision under uncertainty (Huth et al., 2025). A flag forces a choice – cut exposure, modify load, order a review, or monitor more closely – and each carries a cost. So the artefact to demand from a vendor is not a model but a deployment protocol: the exact outcome predicted, the window, the population, the thresholds, the action attached to each, the named human accountable, the cost of a false positive and negative, and the audit once it is live. Without that, a risk score is an over-interpreted dashboard light.
Beyond injury prediction — promising, held to the same bar
Coverage of “AI in performance” collapses into injury prediction and misses where the useful work is. Three applications deserve attention – under the same scepticism. Generative AI for analyst workflows (summarising opposition video, drafting scouting notes, indexing footage) sits at the safe end: a flawed first-pass is corrected by a senior analyst at trivial cost, where a flawed risk flag changes an athlete’s week. Adoption should be tiered by the cost of being wrong. Computer vision for biomechanics has moved from curiosity to a deployable tool – but only for constrained cases under controlled capture; in-competition validity remains well behind the marketing, as the computer-vision deep-dive details. And the athlete-management layer, below, is where the consequential infrastructure decisions are actually made.
The cycling case: a market signal, not a result
The most-watched live experiment in elite AI in 2026 is in cycling. In April, INEOS Grenadiers rebranded as the Netcompany INEOS Cycling Team around a five-year partnership built on Netcompany’s PULSE platform – the same “control-tower” software the firm runs at Heathrow and Munich airports (Netcompany, 2026; Reuters, 2026). The pitch is real-time integration: if a rider’s glucose dips as a crosswind builds, the system flags it and a car delivers a gel before the rider cracks. Within the same window, Visma–Lease a Bike announced its own tie-up with the AI lab Mistral.
The discipline this article owes its own argument: none of this is evidence of performance impact.
A corporate announcement and a sponsorship are statements of ambition, not validated results. Cycling is a clean test of the integration thesis – the sport already drowns in power, position and environmental data, so the bottleneck really is integration not collection – but the thesis is a bet, not a finding. We will only know if PULSE moved the needle when availability and race-outcome metrics improve in a way you can attribute to it. A piece that has spent two thousand words demanding that standard of injury vendors should apply the same standard when the technology is exciting.
The AMS layer: who owns the ground your decisions stand on
The least visible but most consequential AI story is the athlete-management-system layer, where the data lives and decisions get made or quietly avoided. Three firms dominate: Teamworks (a USD 1bn-plus unicorn after a 2025 Series F, having absorbed Smartabase and others), Catapult (which folded GPSports, PlayerTek, SBG and more into its hardware), and Kitman Labs (iP platform across 2,000-plus teams including the NFL, NBA, MLS, NWSL and the 2025 British & Irish Lions tour).
The consolidation matters not for whose logo is on the dashboard, but because the platform owning the integration layer quietly defines what a club can even ask of its own data – and every AI feature on top is only as good as the data discipline beneath it. That is the cost vendors rarely foreground: not the licence fee but the human labour of standardising definitions, cleaning history and auditing drift.
The better question is never “does this platform have AI?” but “can our organisation produce the data quality and governance this feature needs to add value?” – the question that separates mature departments from dashboard collectors.
Our editorial position
We have circled this long enough; a head of performance deserves it plain.
Most AI injury-prediction products sold to elite clubs in 2026 do not meet the evidence bar a serious department should require before a model touches an individual athlete’s week. The strongest review found 98% of models at high or unclear risk of bias and none externally validated. One of the most relevant recent peer-reviewed examples is a fragile single-club study with a likely information-leak and an implied PPV under one percent. The vendor case studies are retrospective and uncontrolled. That is not a reason to refuse the technology – it is a reason to refuse it on the vendors’ terms. And it is worth naming the decision the literature never frames for you: a budget spent on an unproven injury model is a budget not spent on a second physio, better sleep provision, or another analyst – the real choice a performance director faces is rarely “this tool or nothing,” but “this tool or the next-best use of the same money.”
The genuine value of AI in 2026 lies away from individual injury prediction: in integration that shortens the distance between raw signal and a good question; in generative tools that take grunt-work off analysts where the cost of error is a human edit; and in computer vision for constrained screening. And on cycling, AMS and the partnerships, we hold ourselves to the rule we set the vendors – those are signals of where money and ambition are moving, not evidence that any of it has improved a result. We agree with Robertson and colleagues, whose sports-technology quality framework argues for exactly this shift toward evidence, validation and context (Robertson et al., 2023). The headline says ‘a sceptical human,’ but the fuller point is a sceptical system: good data, clear definitions, calibrated probabilities, external validation, explicit cost of error, and a named human who refuses to abdicate the decision. The human still matters most, not because intuition beats technology, but because someone has to carry responsibility for how uncertainty becomes action.
So, the Monday-morning test. If a vendor leads with sensitivity, ask for PPV at your squad’s base rate; if they can’t compute it, the tool should not yet be treated as decision-ready. If they lead with a case study, ask what was validated prospectively in a population like yours. If they lead with a dashboard, ask which decision it changes and who is accountable for it. Run any model silently first – predicting without touching decisions – and check its calibration and alert burden against reality before it earns a vote. These are the questions the evidence forces, not advice from the touchline – the judgement of how they land in a specific squad, with a specific budget and a specific medical team, belongs to the people in the building. But the direction holds: the kit has outrun the scrutiny, and in 2026 the highest-leverage move is not buying more AI, but asking far harder questions about what you have already bought.
How this series is made, and how to read it: this is editorial analysis, not a practitioner’s memoir and not a systematic review. PERFORM’s pieces are researched and drafted with the assistance of AI tools, then reviewed, edited and fact-checked by our editorial team against primary sources – peer-reviewed literature, clearly labelled preprints, industry reports, league and company announcements, and practitioners’ own published work. Where the evidence is strong we say so; where it is limited we treat it as limited; where a claim comes from a vendor or corporate announcement we treat it as a hypothesis, not proof. The views here are our editorial position, drawn from the published record rather than first-hand experience inside an elite performance department. Where practitioners are named or quoted, those words are their own. Where we couldn’t verify a claim, we left it out. And where you have the hands-on experience we’re writing about, we’d rather hear from you than pretend to it.
References
Bullock, G. S., Mylott, J., Hughes, T., Nicholson, K. F., Riley, R. D., & Collins, G. S. (2022a). Just how confident can we be in predicting sports injuries? A systematic review of the methodological conduct and performance of existing musculoskeletal injury prediction models in sport. Sports Medicine, 52(10), 2469–2482. https://doi.org/10.1007/s40279-022-01698-9
Bullock, G. S., Hughes, T., Arundale, A. H., Ward, P., Collins, G. S., & Kluzek, S. (2022b). Black box prediction methods in sports medicine deserve a red card for reckless practice. Sports Medicine, 52(8), 1729–1735. https://doi.org/10.1007/s40279-022-01655-6
Bullock, G. S., Ward, P., Collins, G. S., Hughes, T., & Impellizzeri, F. M. (2024). Comment on: Machine learning for understanding and predicting injuries in football. Sports Medicine – Open, 10(1). https://doi.org/10.1186/s40798-024-00745-1
Ekstrand, J., Hägglund, M., & Waldén, M. (2011). Injury incidence and injury patterns in professional football: The UEFA injury study. British Journal of Sports Medicine, 45(7), 553–558. https://doi.org/10.1136/bjsm.2009.060582
Freitas, D. N., Mostafa, S. S., Caldeira, R., Santos, F., Fermé, E., Gouveia, É. R., & Morgado-Dias, F. (2025). Predicting noncontact injuries of professional football players using machine learning. PLOS ONE, 20(1), e0315481. https://doi.org/10.1371/journal.pone.0315481
Huth, M., Canal-Simón, B., Ferrer, E., Rodas, G., Yanguas, X., Hasenauer, J., & González, J. R. (2025). Informed injury prediction in elite football: Decision theory meets machine learning [Preprint]. medRxiv. https://doi.org/10.1101/2025.04.23.25326218
Impellizzeri, F. M., Tenan, M. S., Kempton, T., Novak, A., & Coutts, A. J. (2020). Acute:chronic workload ratio: Conceptual issues and fundamental pitfalls. International Journal of Sports Physiology and Performance, 15(6), 907–913. https://doi.org/10.1123/ijspp.2019-0864
Impellizzeri, F. M., Woodcock, S., Coutts, A. J., Fanchini, M., McCall, A., & Vigotsky, A. D. (2021). What role do chronic workloads play in the acute to chronic workload ratio? Time to dismiss ACWR and its underlying theory. Sports Medicine, 51(3), 581–592. https://doi.org/10.1007/s40279-020-01378-6
Netcompany. (2026). Netcompany INEOS Cycling Team: Unifying the performance ecosystem [Corporate communication]. Retrieved from https://netcompany.com/netcompany-ineos/
Reuters. (2026, April 28). New AI partnership to propel INEOS Grenadiers back to top, team hopes. Reuters. Retrieved from https://www.reuters.com/sports/cycling/
Robertson, S., Zendler, J., De Mey, K., Haycraft, J., Ash, G. I., Brockett, C., Seshadri, D., Woods, C., Kober, L., Aughey, R., & Rogowski, J. (2023). Development of a sports technology quality framework. Journal of Sports Sciences, 41(22), 1983–1993. https://doi.org/10.1080/02640414.2024.2308435
van den Goorbergh, R., van Smeden, M., Timmerman, D., & Van Calster, B. (2022). The harm of class imbalance corrections for risk prediction models. Journal of the American Medical Informatics Association, 29(9), 1525–1534. https://doi.org/10.1093/jamia/ocac093
Zone7. (2022). Injury risk forecasting: Retrospective validation across professional football teams [Industry report]. Zone7. Retrieved from https://www.zone7.ai